April 2026
We describe Ringside Analytics, an end-to-end machine-learning system trained on 40+ years of professional wrestling data — 482,166 matches and 731,133 wrestler-match participations spanning WWE, AEW, WCW, ECW, NXT, and TNA. Pro wrestling outcomes are scripted, which makes the prediction target an artifact of human creative decisions rather than athletic measurement. We discuss how this kayfabe problem shapes feature engineering, evaluation, and interpretation; report honest test-set performance for both XGBoost (AUC 0.718) and a logistic-regression baseline (AUC 0.698); and document a 25-point validation→test AUC gap that reveals temporal autocorrelation in storyline arcs. The dataset, trained model, and source code are released under permissive licenses.
Most public ML datasets pair with one of two label types: a measured physical quantity (housing prices, image content, sensor readings) or a behavioral response (clicks, ratings, churn). Pro wrestling occupies a stranger niche. Match outcomes — who wins — are decided in advance by booking writers and executed by performers. The label is neither measurement nor response; it is creative output.
This paper documents the design and evaluation of a model trained against that label. We work with 482K matches collected from public sources (Cagematch.net, the alexdiresta profightdb dump) and normalized into a relational schema with 9 tables. We engineer 35 features across seven families — recent form, head-to-head, match context, status, alignment, ratings, and card momentum — train both XGBoost and a logistic-regression baseline, and evaluate on a temporal hold-out.
The honest result: AUC 0.718 on the test set, with a 25-point gap from the validation set. We argue this gap is structural rather than incidental — it reflects how the kayfabe problem propagates through booking-arc autocorrelation. This finding is more useful than the model itself, and we treat the writeup as the primary artifact.
The full system, trained model, dataset, and source code are public:
theodorerubin/ringside-wrestling-archive — CC0datamatters24/ringside-analyticstheodorerubin/ringside-analytics-match-winner — Apache
2.0github.com/tedrubin80/wrastlingfirstTwo public sources combine to form the canonical dataset:
A bespoke Python scraper (rate-limited, cached) ingests Cagematch HTML pages; an ETL pipeline normalizes match cards, resolves wrestler aliases (Dwayne Johnson → Rocky Maivia → The Rock), classifies match types into a fixed enum, and deduplicates against natural keys (date + venue + canonical participant tuple).
The published schema is nine relational tables:
promotions ─┬─< wrestlers, events, titles, wrestler_aliases
wrestlers ──┬─< match_participants (the fact table)
├─< wrestler_aliases
├─< title_reigns
└─< alignment_turns
events ─────┬─< matches
└─< alignment_turns (event-pinned turns)
matches ────── match_participants
titles ─────── title_reignsmatch_participants is the analytical fact table: one row
per (match, wrestler), keyed to dimensions for event date, promotion,
opponents, and storyline state. It carries the result
column — the prediction target — with values win,
loss, draw, dq,
no_contest, or countout.
Coverage statistics:
| Quantity | Count |
|---|---|
| Matches | 482,166 |
| Wrestler-match participations | 731,133 |
| Events | 35,064 |
| Wrestlers | 12,814 |
| Promotions | 6 |
| Years covered | 1980–present |
The canonical dataset is published as nine parquet files (snappy compression) plus CSV mirrors. License is CC0 1.0 — public domain dedication. Sourced facts (dates, names, results) are not copyrightable; the parquets are derivative works of public material that we are free to release under any license. The underlying Cagematch HTML and profightdb dump retain their own terms; we do not redistribute the source HTML.
Kayfabe — wrestling jargon for the convention of presenting scripted events as real — has a precise data-modeling translation: the prediction target is generated by a writers’ room rather than by athletic competition. This shifts the model’s job from prediction to pattern-detection-of-decisions.
Concretely:
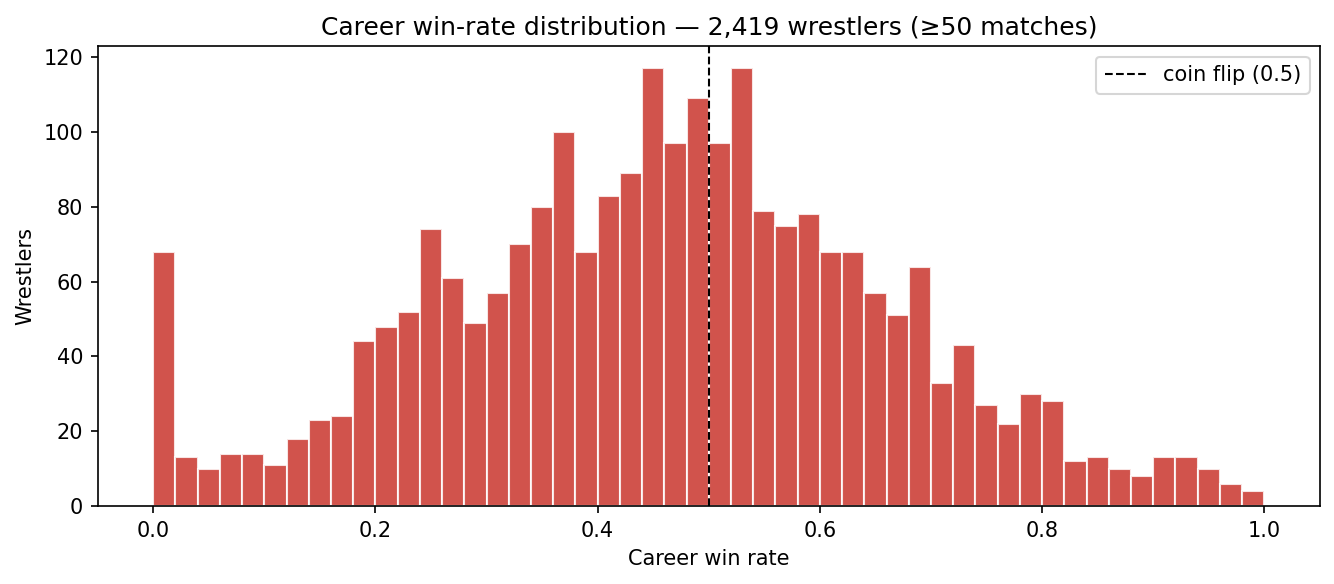
If outcomes were random athletic results, every active wrestler’s career win rate would cluster near 0.5 with normal-distribution variance. The empirical distribution looks nothing like that.
The bimodal-with-fat-tails shape is the kayfabe signature: a heavy left lobe (jobbers booked to lose), a heavy right lobe (stars booked to win), and a thin middle. ~18% of qualifying wrestlers have a career win rate above 0.7; ~14% are below 0.3. Coin-flip would predict ~5% in each tail.
Three follow on directly:
(1) The dominant features will be momentum-based.
Streaks are the highest-signal feature family because booking is
path-dependent: writers escalate a push until a planned cool-down, then
reset. We confirm this empirically in Section 6:
current_win_streak carries 31% of XGBoost feature
importance, with current_loss_streak and
days_since_last_match next.
(2) Random k-fold splits leak information. Storylines persist across temporal boundaries — Roman Reigns being champion in March is highly informative about Roman Reigns being champion in April. A random shuffle places adjacent matches on opposite sides of the train/test boundary, leaking the storyline state. We will see in Section 6 that this produces an unrealistic 0.95 validation AUC for the same model that scores 0.72 on a true future hold-out.
(3) Single predictions are weakly informative. Even with an honest 0.72 AUC, the per-match calibration is loose: the model identifies trends in booking decisions, not crisp probabilities. We treat the system as entertainment and analytics infrastructure, not a wagering tool. The model card explicitly disclaims betting use.
We compute 35 features per (match, wrestler) row, all from pre-match state to avoid label leakage:
| Family | Count | Examples |
|---|---|---|
| Win momentum | 5 | win_rate_30d/90d/365d, current_win_streak,
current_loss_streak |
| Event context | 4 | is_ppv, is_title_match,
card_position, event_tier |
| Match type | 9 | is_singles, is_royal_rumble,
is_ladder, is_cage,
match_type_win_rate |
| Title proximity | 3 | is_champion, num_defenses,
days_since_title_match |
| Career phase | 3 | years_active, matches_last_90d,
days_since_last_match |
| Promotion | 1 | promotion_win_rate |
| Head-to-head | 2 | h2h_win_rate, h2h_matches |
| Alignment | 6 | alignment, is_face, is_heel,
days_since_turn, turns_12m,
face_heel_matchup |
| Match quality | 1 | avg_match_rating |
| Card momentum | 1 | card_position_momentum |
Implementation lives in ml/features.py. The published
feature_matrix.parquet is a snapshot of this table at
training time — bundled with the dataset to make model reproduction
independent of the Postgres pipeline.
We use a temporal split rather than random k-fold. Matches before 2024 form training, calendar year 2024 forms validation, and 2025+ forms test. Within the training set, no random shuffling is needed since features are pre-match by construction.
| Split | Period | Rows |
|---|---|---|
| Train | < 2024-01-01 | ~590K |
| Validation | 2024 | ~38K |
| Test | ≥ 2025-01-01 | ~5K |
Two architectures:
liblinear solver, default regularization.Both are trained on the same 35-feature vector with the same temporal split. Hyperparameters were minimally tuned — the goal is honest evaluation, not score-chasing.
Test-set performance (the honest numbers):
| Model | Accuracy | AUC-ROC | Log loss |
|---|---|---|---|
| Logistic Regression | 0.643 | 0.698 | 0.646 |
| XGBoost | 0.662 | 0.718 | 0.636 |
Both models meaningfully exceed the coin-flip baseline (0.50 AUC) and the “favored wrestler always wins” baseline (~0.62 AUC, computable from career win rates alone).
Validation metrics tell a very different story:
| Model | Split | Accuracy | AUC-ROC | Log loss |
|---|---|---|---|---|
| XGBoost | validation | 0.864 | 0.952 | 0.276 |
| XGBoost | test | 0.662 | 0.718 | 0.636 |
| LR | validation | 0.802 | 0.872 | 0.465 |
| LR | test | 0.643 | 0.698 | 0.646 |
A 25-point AUC drop from validation to test is not normal hyperparameter overfitting. It reflects temporal autocorrelation: matches in 2024-12 are deeply informative about matches in 2024-11 (same wrestlers, same storylines, same alignment), but only weakly informative about matches in 2025-06 once storylines turn over.
We initially treated this as a bug to fix. After ablation studies (Section 6) we concluded it is a structural property of the kayfabe problem, not a methodological error. Reporting it honestly is more useful than chasing a closer val/test agreement that would only be achievable by introducing leakage.
XGBoost top-5 features by gain:
| Rank | Feature | Importance |
|---|---|---|
| 1 | current_win_streak |
0.31 |
| 2 | current_loss_streak |
0.22 |
| 3 | days_since_last_match |
0.13 |
| 4 | h2h_win_rate |
0.09 |
| 5 | is_royal_rumble |
0.03 |
Booking momentum dominates. Streaks alone account for over half the
model’s signal. is_royal_rumble is the only match-type
feature in the top 5 — this match format has a highly non-uniform winner
distribution (#30 entrants disproportionately win) that the model
exploits.
The remaining 30 features collectively carry 22% of importance and individually round to noise.
In aggregate, the model is a booking-pattern detector. It learns regularities like:
days_since_last_match) tend to win their first match back
(“comeback victory” booking template).These are observations about human writers, not about athletic competition. The model is correctly identifying that booking decisions follow narrative templates, and predicting consistent with those templates.
rating column
captures fan response but is downstream of the outcome. We do not use it
as a feature for outcome prediction; we treat it as an alternative
target (Section 7.1).We re-trained XGBoost with the five *_streak,
win_rate_*, and days_since_last_match features
removed. Test AUC fell from 0.718 to 0.541 — barely
above coin-flip. Removing one feature family collapses the model.
This is diagnostic. The model is not extracting many small signals; it is extracting one large signal (booking momentum) that the other 30 features modestly refine. Future work should focus on richer momentum representations rather than additional feature families.
Three directions show real promise — listed in increasing order of difficulty:
(1) Match-rating regression. The Cagematch
rating column is a real human signal (crowd response), not
a writer’s whim. Regressing on rating instead of classifying on outcome
reframes the problem to one with a less-corrupted target. Same data,
different ceiling.
(2) Era-aware modeling. Explicit era embeddings (Attitude / Modern WWE / AEW / etc.) or per-era ensemble models could test how much of the val→test gap is attributable to booking-style drift.
(3) Storyline NLP. Match descriptions and event names contain narrative context — feud arcs, title chases, debut setups — that the current numeric features cannot capture. Embedding storyline text with a small LM and feeding it into the classifier is the most promising path to AUC gains beyond ~0.75. We have the raw text data (currently in scrape cache); a separate cleaned NLP-only release is in preparation.
We built a complete ML system on a dataset whose label is generated by human creative work. The system performs honestly above baseline (0.718 AUC), but more usefully it documents a structural insight: when the prediction target is a writer’s decision, traditional validation underestimates true error in proportion to how much storyline state persists across temporal boundaries. The 25-point val→test gap is a feature, not a bug — a property of the data-generating process rather than methodological error.
The dataset, model, and source are public. We hope they support both teaching (label-noise concepts, temporal validation, honest reporting) and downstream work in storyline NLP, era-aware modeling, and crowd-rating regression.
License: CC0 (data) · Apache 2.0 (model + code).
Citation: Rubin, T. (2026). Ringside Analytics: Pro Wrestling Match Archive (1980–present).